Introduction to Bitcoin Heuristics

There are two major bitcoin heuristics to clustering an entity: common-input-ownership heuristic and change address detection heuristic.
In a single transaction, common-input-ownership heuristic assumes the input address is all from one entity. There are cases, however, where input addresses can be of multiple entities. This is called coinjoin, and would break this assumption. (e.g. address 3 in the image below)

Change address detection heuristic utilizes the characteristics of UTXO. As it is difficult to send the exact specified amount of funds to the receiver, the remainder of the funds are to be returned to the entity via change address. Hence, change address detection is necessary as it’s part of the entity. In this post, we will focus on the heuristics of change address detection.
Change address detection heuristic
Our company primarily focuses on researching the most reliable heuristics in detecting clusters. Here are some of the methods that we have stumbled upon while developing our heuristics, and our insights on them.
Address reuse
This method detects change the address by checking the output addresses. If there exists an address that was never previously observed, there’s a high chance that it’s a change address. This is because the purpose of creating a new address in a transaction is to return the remaining funds.
To use this heuristic, it has to match the conditions below.
The address must not have been previously observed
It has to be the ONLY address to not been observed before
The heuristic is rather simple, but it is one of the most commonly used. We believe that this method is capable of detecting change address in many cases.
Detection using decimal places
The length of decimal places in a change address’s value is assumed to be much longer than any other output addresses. This is possible because nowadays each transaction carries a transaction fee, and the specified amount of funds in a transaction tends to be reduced in precision for rapid human interpretation of annotation (e.g. you would just send $5 to your friend instead of sending $4.93).
It is important to note that in the past, there were a considerable amount of transactions that had reduced precision value for change address, but nowadays all output addresses contain decimals. Hence, finding the right parameters are essential for correctly detecting the change address.
In our implementation, we first search for an address with decimal length greater than 7. If all other output value’s decimal lengths are less than 2, then the address is accepted as a change address (the two parameters may be adjusted to enhance performance). Though this heuristic has many exceptions due to its simplicity, as long as the difference between the two parameters is large, it can perform decently.
Equal-Output Coinjoin
As previously explained, coinjoin is a case where input addresses come from multiple entities. These entities send the exact amount of funds to multiple addresses, increasing the level of anonymity.

In the figure above, address 21 and address 32 has the same output value. This makes it hard to differentiate which entity has sent the fund to address 21 and address 32. However, it is possible to determine the change address by simply calculating the difference of the output value from the subset-sum of input values (e.g (0.006 + 0.005) — 0.01 = 0.001). The problem with coinjoin is that we have to handle two or more entities from one transaction.
In our implementation:
Determine if the transaction is coinjoin by checking if two or more output values are equivalent
If condition 1 is true, increase the number of entity to cluster
Currently, we assume the number of entities is equal to the number of outputs with equivalent values.
It is essential to implement cases where the number of inputs does not equal to the number of outputs with equivalent values, to accurately estimate entities.
Script Type
It is highly probable that an entity would use only one script type throughout a transaction. This implies that if all input addresses have the same script type while output addresses aren’t, the output address with the script type identical to the input addresses is the change address.
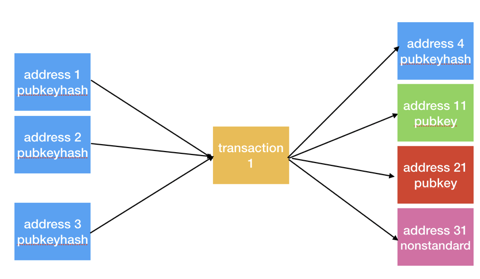
In the figure above, we can infer that address 4 is the change address as it is the only output address with the same script type.
Round numbers
This heuristic assumes that the payment amount is usually some reduced precision number, such as $5.50 or $19.00. With this assumption, an output address with a value that isn’t reduced in precision is considered to be the change address. The problem with this method is that the number could be in some form of reduced precision in a different currency (e.g. USD). Hence, we need to import the exchange rate at the time frame of when the transaction had occurred, but the cost of resources outruns the performance.
Unnecessary input heuristic
This heuristic is based on the logic of what need not spent, stays. For example, we have:
2 + 3 → 4 + 1, where left: input amount, right: output amount
If we wanted to send 1BTC, we would have only needed to send one of the two input addresses. However, because we sent 4BTC, we needed both of those addresses.
The problem with this method is that there are wallets that use coin selection algorithms that do not fit into this logic.
This heuristic has not been used due to the issue stated above. Moreover, the performance of the method itself was low.
Conclusion
We have explored some of the most widely known bitcoin entity clustering heuristics. Based on our experience with these techniques, we were able to spot many flaws in these methods, hence making the cluster unreliable. This is why our company strives for developing robust algorithms that will effectively cluster entities.